이전 게시글의 결과를 분석하면
현재 상태 분석
| ✅ cuDNN 사용 확인 | Loaded cuDNN version 8100 → 정상 |
| ✅ GPU 인식됨 | GTX 1050, 2775MB 사용 중 |
| ✅ 훈련 진행됨 | Epoch 27까지 무사히 진행 중 |
| ⚠️ GPU 사용률 낮음 | 이미지상 1~3% 수준 유지 |
| ⚠️ Epoch당 평균 시간 | 약 12분(Epoch 1) ~ 14분(Epoch 26) |
| ⚠️ 발열 | 온도 90도 이상 유지, 냉각 부족 가능성 |
| ✅ 정확도 향상 곡선 정상 | Epoch 1: acc 1% → Epoch 26: acc 32.8%, val_acc 60.2% |
- 주요 병목 현상 원인 : 1. GPU 연산 비중이 낮고, 병렬처리 최적화 부족
- GPU가 활성화돼 있어도 연산을 효율적으로 활용 못 하고 있음 (1~3% 사용률)
- 주요 원인:
- TensorFlow 연산 중 일부가 여전히 CPU fallback 중
- Data pipeline(입력 이미지 처리)이 병목
- 모델 구조상 cuDNN이 최적 커널을 사용하지 못함 (특히 DenseNet 계열)

이에 따라 실행시간 단축을 위해 MobileNetV2 모델로 변경하여 수행
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import GlobalAveragePooling2D, Dense, Dropout, Rescaling
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.utils import image_dataset_from_directory
from tensorflow.keras.callbacks import EarlyStopping
import pathlib
import pickle
import matplotlib.pyplot as plt
# ✅ GPU 메모리 자동 증가 설정
gpus = tf.config.list_physical_devices('GPU')
if gpus:
try:
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
print(f"{len(gpus)} GPU(s) available.")
except RuntimeError as e:
print(e)
else:
print("GPU not found.")
# ✅ 데이터 경로 설정
data_path = pathlib.Path('datasets/stanford_dogs/images/images')
# ✅ 원본 데이터셋 생성 및 클래스 이름 추출
train_ds_raw = image_dataset_from_directory(
data_path,
validation_split=0.2,
subset='training',
seed=123,
image_size=(224, 224),
batch_size=4
)
test_ds_raw = image_dataset_from_directory(
data_path,
validation_split=0.2,
subset='validation',
seed=123,
image_size=(224, 224),
batch_size=4
)
# ✅ 클래스 이름 저장 (prefetch 전에 추출)
class_names = train_ds_raw.class_names
with open('dog_species_names.txt', 'wb') as f:
pickle.dump(class_names, f)
# ✅ 데이터 성능 최적화 (cache + prefetch)
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds_raw.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = test_ds_raw.cache().prefetch(buffer_size=AUTOTUNE)
# ✅ 사전 학습된 MobileNetV2 모델 로딩
base_model = MobileNetV2(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
base_model.trainable = False # 전체 동결 (추후 일부 fine-tuning 가능)
# ✅ 전체 모델 구성
cnn = Sequential([
Rescaling(1.0 / 255.0),
base_model,
GlobalAveragePooling2D(),
Dense(512, activation='relu'),
Dropout(0.5),
Dense(120, activation='softmax') # 120개의 견종
])
# ✅ 컴파일
cnn.compile(
loss='sparse_categorical_crossentropy',
optimizer=Adam(learning_rate=1e-4),
metrics=['accuracy']
)
# ✅ EarlyStopping 콜백 설정
earlystop = EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True)
# ✅ 모델 학습
hist = cnn.fit(
train_ds,
epochs=30,
validation_data=test_ds,
verbose=2,
callbacks=[earlystop]
)
# ✅ 평가 및 저장
test_acc = cnn.evaluate(test_ds, verbose=0)[1]
print(f'정확률 = {test_acc * 100:.2f}%')
cnn.save('mobilenetv2_dog_classifier.h5')
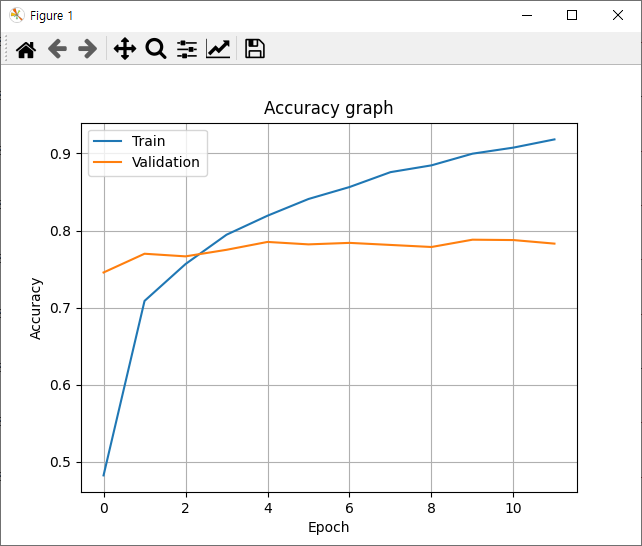
# ✅ 정확도 시각화
plt.plot(hist.history['accuracy'])
plt.plot(hist.history['val_accuracy'])
plt.title('Accuracy graph')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'])
plt.grid()
plt.show()
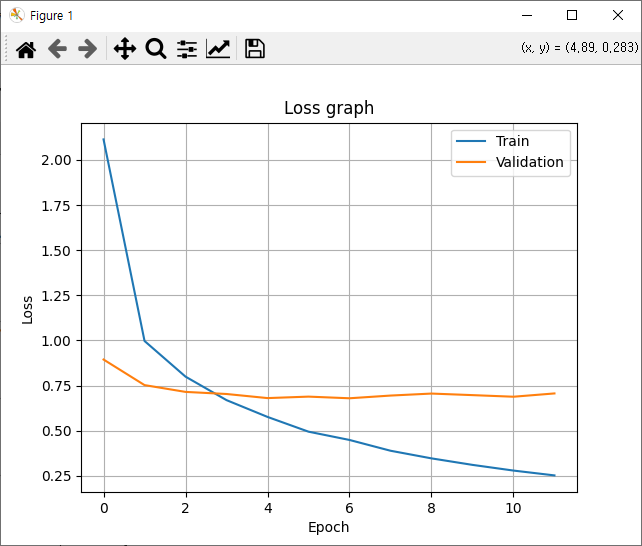
# ✅ 손실 시각화
plt.plot(hist.history['loss'])
plt.plot(hist.history['val_loss'])
plt.title('Loss graph')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'])
plt.grid()
plt.show()실행 결과는 다음과 같다.
(tf310) C:\Users\ksseo\Downloads\source_4548_1\source\ch8>python 8-7-MobileNetV2.py
1 GPU(s) available.
Found 20580 files belonging to 120 classes.
Using 16464 files for training.
2025-07-19 16:53:45.437421: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2025-07-19 16:53:46.000395: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1616] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 2775 MB memory: -> device: 0, name: NVIDIA GeForce GTX 1050, pci bus id: 0000:01:00.0, compute capability: 6.1
Found 20580 files belonging to 120 classes.
Using 4116 files for validation.
Epoch 1/30
2025-07-19 16:53:54.346380: I tensorflow/stream_executor/cuda/cuda_dnn.cc:384] Loaded cuDNN version 8100
4116/4116 - 115s - loss: 2.1133 - accuracy: 0.4825 - val_loss: 0.8946 - val_accuracy: 0.7456 - 115s/epoch - 28ms/step
Epoch 2/30
4116/4116 - 105s - loss: 0.9972 - accuracy: 0.7088 - val_loss: 0.7530 - val_accuracy: 0.7699 - 105s/epoch - 26ms/step
Epoch 3/30
4116/4116 - 106s - loss: 0.7998 - accuracy: 0.7566 - val_loss: 0.7154 - val_accuracy: 0.7665 - 106s/epoch - 26ms/step
Epoch 4/30
4116/4116 - 107s - loss: 0.6698 - accuracy: 0.7946 - val_loss: 0.7038 - val_accuracy: 0.7750 - 107s/epoch - 26ms/step
Epoch 5/30
4116/4116 - 107s - loss: 0.5769 - accuracy: 0.8192 - val_loss: 0.6811 - val_accuracy: 0.7852 - 107s/epoch - 26ms/step
Epoch 6/30
4116/4116 - 109s - loss: 0.4952 - accuracy: 0.8409 - val_loss: 0.6892 - val_accuracy: 0.7821 - 109s/epoch - 27ms/step
Epoch 7/30
4116/4116 - 108s - loss: 0.4493 - accuracy: 0.8564 - val_loss: 0.6801 - val_accuracy: 0.7840 - 108s/epoch - 26ms/step
Epoch 8/30
4116/4116 - 108s - loss: 0.3897 - accuracy: 0.8757 - val_loss: 0.6951 - val_accuracy: 0.7813 - 108s/epoch - 26ms/step
Epoch 9/30
4116/4116 - 108s - loss: 0.3473 - accuracy: 0.8845 - val_loss: 0.7061 - val_accuracy: 0.7787 - 108s/epoch - 26ms/step
Epoch 10/30
4116/4116 - 108s - loss: 0.3113 - accuracy: 0.8997 - val_loss: 0.6975 - val_accuracy: 0.7881 - 108s/epoch - 26ms/step
Epoch 11/30
4116/4116 - 108s - loss: 0.2798 - accuracy: 0.9076 - val_loss: 0.6887 - val_accuracy: 0.7877 - 108s/epoch - 26ms/step
Epoch 12/30
4116/4116 - 108s - loss: 0.2531 - accuracy: 0.9182 - val_loss: 0.7069 - val_accuracy: 0.7830 - 108s/epoch - 26ms/step
정확률 = 78.40%
'딥러닝' 카테고리의 다른 글
| 8.8 [비전 에이전트 7] 견종 인식 프로그램 (0) | 2025.10.05 |
|---|---|
| 컴퓨터 비전과 딥러닝 미세 조정 방식의 전이 학습 : 견종 인식하기 (0) | 2025.07.19 |
| 정규화 절단 알고리즘으로 영역 분할하기(프로그램 4-6) (3) | 2025.07.09 |




