반응형
라즈베리파이에 라즈비안 OS를 설치하면 기본적으로 최신의 python이 설치되어 있다. 여기서는 v 3.11.2가 설치되어 있는 것을 다음과 같이 확인할 수 있다.

tensorflow를 설치하기 위해서는 python 버전이 3.10.x 버전을 설치하여야 한다. 따라서 하나의 라즈베리파이에 여러 개의 python 버전이 동작해야 하고, 내가 필요한 python v3.10.x를 사용하기 위해서는 가상환경을 사용하는 것이 좋다.
그래서 아나콘다(Anaconda)를 설치하려고 하였으나 라즈베리파이 5에서는 Anaconda 대체로 Miniforge를 설치하여야 한다고 한다. 따라서 Miniforge를 설치하였다.
1. 시스템 업그레이드
$ sudo apt update && sudo apt upgrade -y // 우선 패키지 관리자를 최신으로 변경하고 OS 패키지를 최신으로 변경함
2. Miniforge (Anaconda 대체) 설치 - ARM 지원
$ wget https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-Linux-aarch64.sh
$ chmod +x Miniforge3-Linux-aarch64.sh
$ ./Miniforge3-Linux-aarch64.sh- 설치 후 활성화
$ source ~/miniforge3/bin/activate
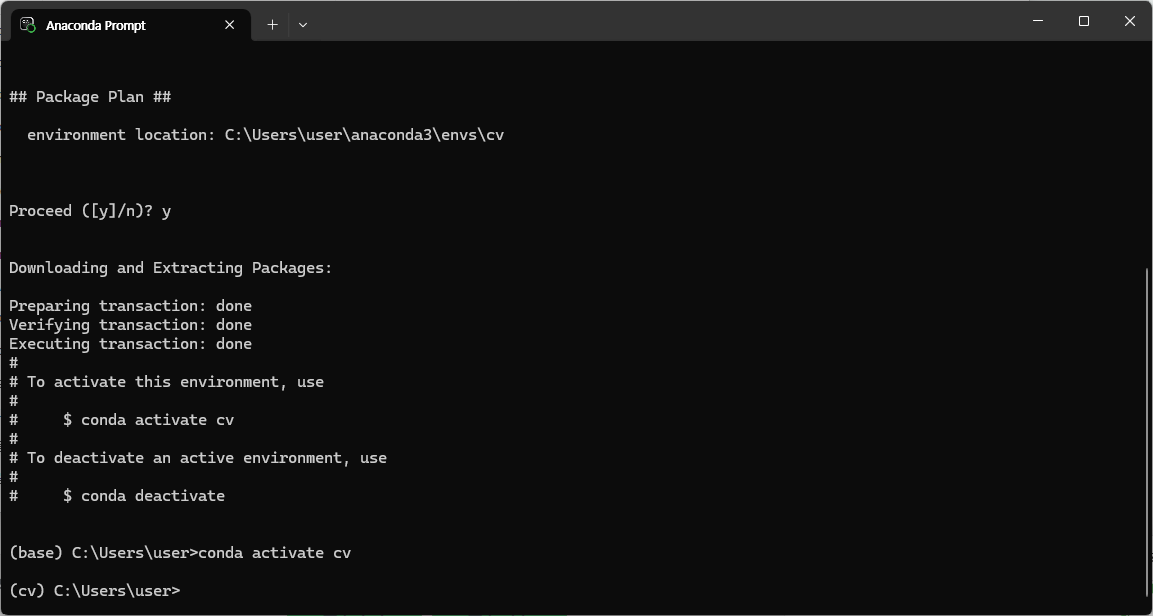
3. 가상환경 생성 및 활성화
$ conda create -n tf python=3.10 -y // 가상환경 tf를 python 버전 3.10.x로 생성
$ conda activate tf // 가상환경 tf를 활성화4. OpenCV 설치
4.1 conda-forge 채널 이용
$ conda install -c conda-forge opencv
4.2 pip를 사용하여 설치
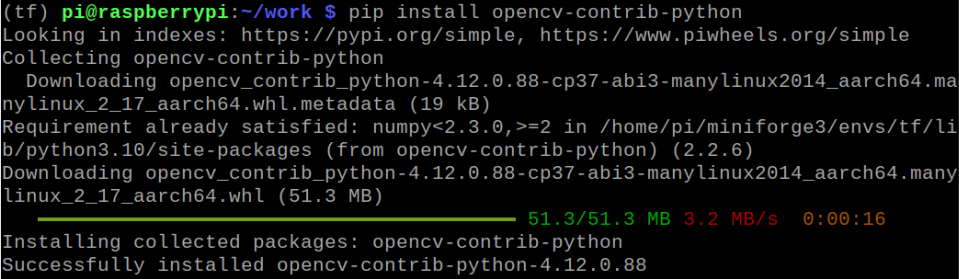
$ pip install opencv-python
$ pip install opencv-contrib-python
4.3 필요한 경우 추가 의존성 설치
$ sudo apt update
$ sudo apt install libopencv-dev python3-opencv4.4 설치 확인
$ python -c "import cv2; print(cv2.__version__)"
반응형
'라즈베리파이' 카테고리의 다른 글
| harris.py (0) | 2025.09.20 |
|---|---|
| laplacian.py (0) | 2025.09.20 |
| mediapip.py (0) | 2025.09.19 |
| point_mediapipe.py (0) | 2025.09.19 |
| sobel.py (0) | 2025.09.19 |